工具箱是OCR文档自学习所提供的用于模型、模板路由分类及提升识别准确率的小工具集合,当前主要提供了分类器与字段类型两大类工具。
分类器管理
分类器:是一个支持多模板、多模型分类路由的工具。用户通过设定分类器中的关键词或训练样本建立分类标准,完成对于已发布的自定义模板、信息抽取模型的自动匹配。用户可在分类器发布后,仅通过分类器接口实现多种类型业务数据的结构化识别及信息提取,省去单一模板或模型接口调用前数据人工分类成本。同时用户可手动通过重复发布,调整分类器所包含的类别。
重要
分类器中仅可选择已完成发布模板或已上线部署完成的模型
分类器需包含至少2个分类
分类器暂不支持长文档模型
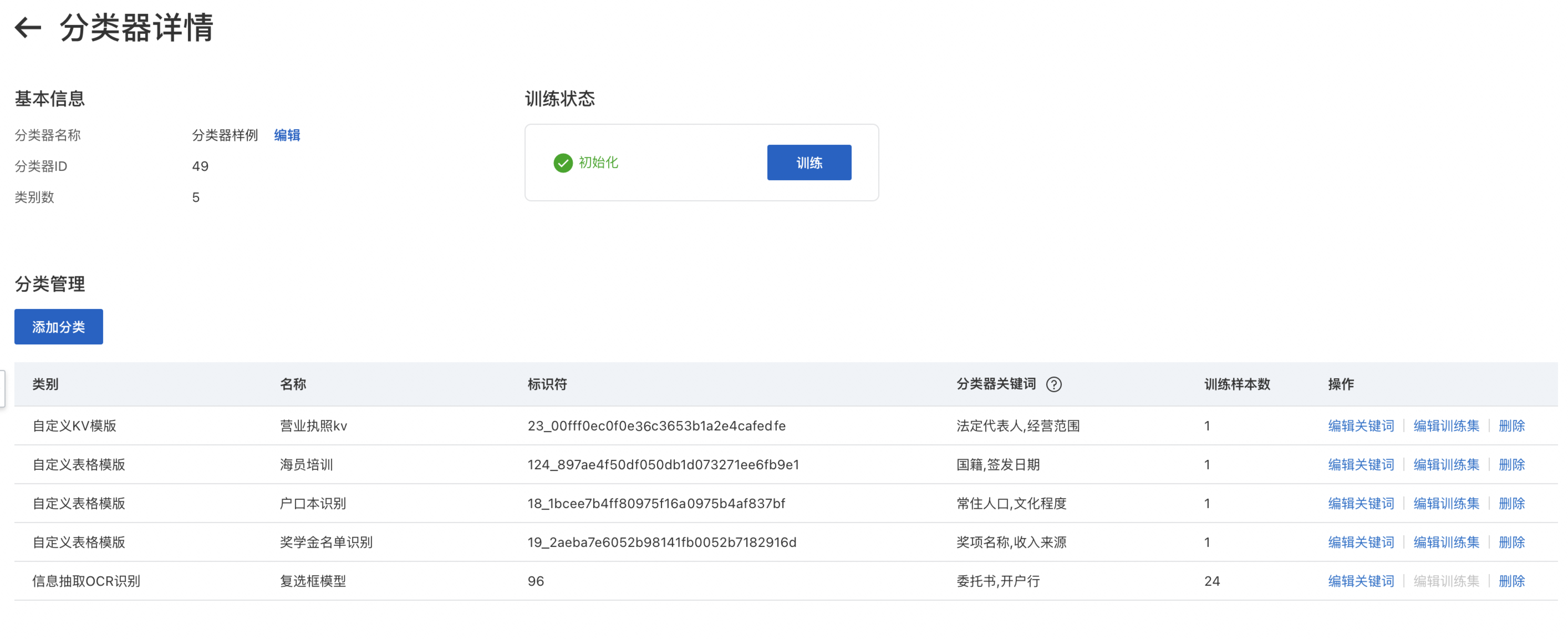
关键词:每一分类数据中存在的独有的文字内容,用于模板或模型与输入图片的匹配。关键词需选择仅在当前模板/模型中出现,即可根据关键词唯一确定图片所属类别。例如,创建身份证与户口本的分类器,户口本识别的关键词可选择“文化程度”、“服务处所”、“证件编号”等,身份证识别的关键词仅可选择“公民身份号码”。
训练集:针对模板类型任务,可通过上传相同版式的图片压缩包,提升分类准确率。尤其是针对数据版式较为复杂的模板,建议上传不少于20张以上不重复的同版式图片。
体验:针对已完成训练的分类器,可进行分类效果体验。
字段类型管理
字段类型:在自学习平台字段识别、抽取过程中增加一些通用、或业务/行业知识的字典用于字段纠错与格式归一化,从而提升字段识别准确率及规范字段输出。
通用字段:即系统预先设置的具备通用属性特征的字段类型。
自定义字段:即用户可根据业务特征自定义创建独有的字段类型,主要通过字典枚举进行新增,例如,全国省市行政规划、候选人名单列表、星期等。
文档内容是否对您有帮助?